Je créé ce fil pour discuter des documents dans un contexte Solid.
Le document est un des fondements de HTTP et permet de faire des déclarations à propos de chose(s) dans un contexte donné. Techniquement, au sens de Solid, il permet de faire des paquets de triplets RDF, ou de regrouper des triplets (chose composé de 3 composants).
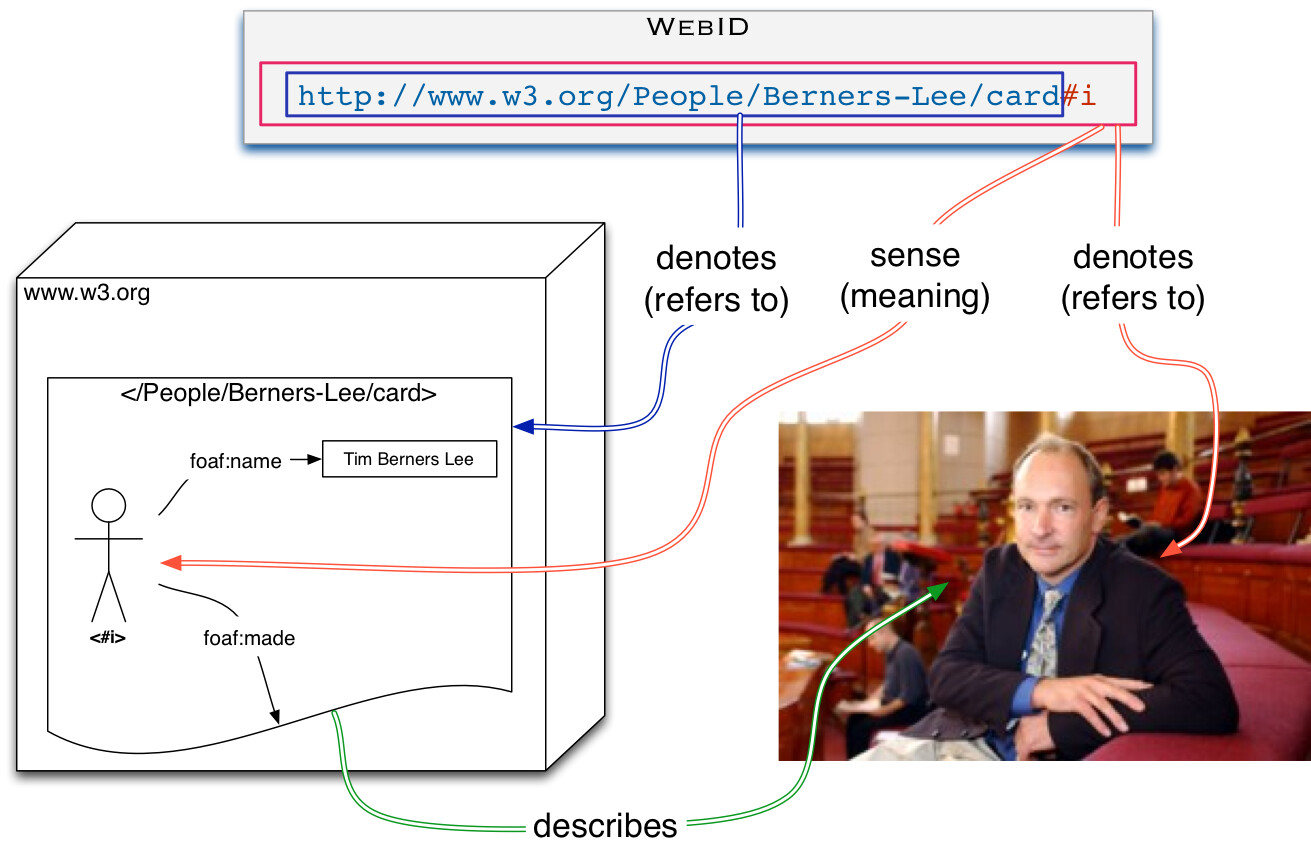
La spec WebID montre un exemple de ce besoin et particulièrement la section 3. The WebID HTTP URI : « When using URIs, it is possible to identify both a thing (which may exist outside of the Web) and a Web document describing the thing. For example, the person Bob is described on his homepage. Alice may not like the look of the homepage, but may want to link to the person Bob. Therefore, two URIs are needed, one for Alice and one for the homepage or a RDF document describing Alice. »
La section 4. Overview de WebID montre un schéma du lien entre le document et la chose représentée (Tim B. Lee en l’occurrence).
Sur le web et sur un POD on doit pouvoir exprimer plusieurs versions d’une réalité. On doit pouvoir exprimer différents points de vue. On doit pouvoir dire des choses contradictoires à propos de soi ou de n’importe quoi. Sur un POD je dois pouvoir me présenter plus ou moins agé par exemple :
Le document accessible à l’URL https://example.org/monPOD/jeune (turtle) :
<https://example.org/monPOD/profile#moi> ex:age "18"^^xsd:integer.
Doit pouvoir donner une version différente de mon âge déclaré dans le document https://example.org/monPOD/moinsJeune (turtle) :
<https://example.org/monPOD/profile#moi> ex:age "54"^^xsd:integer.
Dans les deux documents on parle bien du même sujet (https://example.org/monPOD/profile#moi).
Un POD doit également me permettre de contextualiser des déclarations identiques mais qui n’ont pas la même valeur. Par exemple, pour reprendre l’exemple de Henry Story, je peux avoir un document de mon médecin et un de mon barman me disant tous les deux de prendre de l’apirine mais cela n’aura pas la même valeur.
Le document du médecin https://example.org/monPOD/medecin (turtle) :
<https://example.org/monPOD/profile#moi> ex:doitPrendre <https://www.wikidata.org/wiki/Q18216>.
Peut contenir des triplets identiques à celui de mon barman https://example.org/monPOD/barman (turtle) :
<https://example.org/monPOD/profile#moi> ex:doitPrendre <https://www.wikidata.org/wiki/Q18216>.
La structure sous-jacente du POD doit permettre de différencier les informations afin d’afficher les bonnes en fonction du contexte demandé (l’URL du document).
Avec un triple store les triplets RDF ne sont pas contextualisés. Si on prend les exemples précédents, le triple store va contenir (turtle) :
<https://example.org/monPOD/profile#moi> ex:age "18"^^xsd:integer.
<https://example.org/monPOD/profile#moi> ex:age "54"^^xsd:integer.
<https://example.org/monPOD/profile#moi> ex:doitPrendre <https://www.wikidata.org/wiki/Q18216>.
Comment différencier les deux versions de mon âge ? Qui m’a dit de prendre des médicaments ?
C’est pourquoi Tim B. Lee et Henry Story expliquent qu’il faut un quad store, c’est à dire un triple store capable de stocker un 4 élément : le graphe (ou document ou named graph) auquel appartient le triplet.
Le store ressemblerait donc à (TriG) :
https://example.org/monPOD/jeune {
<https://example.org/monPOD/profile#moi> ex:age "18"^^xsd:integer
}
https://example.org/monPOD/moinsJeune {
<https://example.org/monPOD/profile#moi> ex:age "54"^^xsd:integer
}
https://example.org/monPOD/medecin {
<https://example.org/monPOD/profile#moi> ex:doitPrendre <https://www.wikidata.org/wiki/Q18216>
}
https://example.org/monPOD/barman {
<https://example.org/monPOD/profile#moi> ex:doitPrendre <https://www.wikidata.org/wiki/Q18216>
}