Hello,
Via ce post, je souhaite anticiper la communication sur la décentralisation des données Semapps, le jour où nous passerons de 1 serveur à « N » serveurs.
L’objectif est que dès le début, lorsqu’on demande les informations aux utilisateurs (qui sont à l’origine des données), ces derniers comprennent bien le cycle de vie que ces données vont vivre.
Et pour cela, je souhaite faire un schéma, qui pourra être partagé pour tous les projets qui ont vocation à être « distribués ».
Je viens de faire un point avec Valentin Noilhetas pour le projet Glocal Low-tech
Ils bossent sur un sondage pour récupérer des données du terrain, et j’aimerais donc faire un schéma pour expliquer la VISIO SEMAPPS (= les différentes étapes de « décentralisation » d’un semapps à moyen terme).
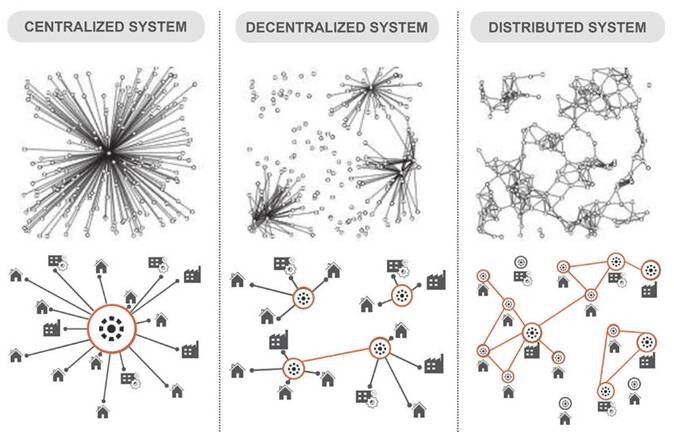
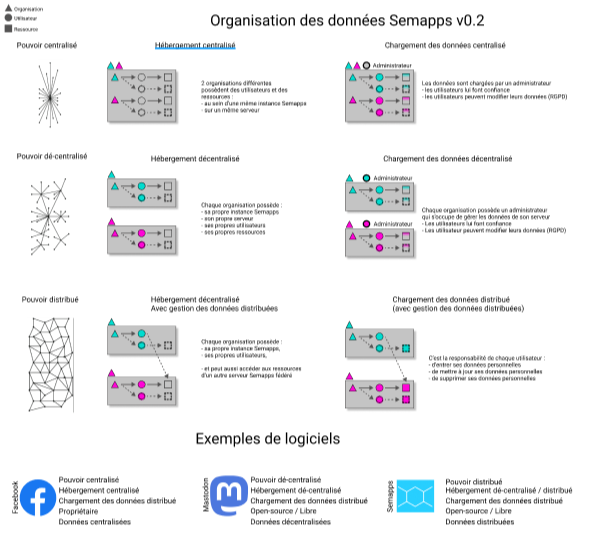
En effet, pour l’instant, dans chacun de nos projets, nous utilisons des instances de Semapps « centralisées », en attendant la férération des Semapps en cours de dev.
Les personnes qui participent au renseignement des données peuvent ne pas comprendre quel est l’utilité de les intégrer dans un Semapps plutot qu’un autre outil centralisé (à part le côté open data ++, qui est déjà cool…).
Donc pour de nombreux projets, nous allons devoir expliquer comment, à l’avenir, grâce à l’interopérabilité entre les Semapps, les données vont se rapprocher de ceux qui les maintiennent.
Je propose donc de commencer à dessiner un schéma (qui me servira pour GLT) qui propose 3 étapes :
- Etape 1 : sondage (RGPD) + saisie des données > Centralisation dans un seul Semapps
- Etape 2 : validation du terrain qu’ils sont bien OK que leurs données sont hébergées comme ils l’entendent.
- Etape 3 : chacun son semapps ! > On déplace les données sur de multiples serveur SOLID en fonction des orgas présentes dans le Semapps d’origine.
Par exemple, Glocal commencerait par un serveur Semapps, puis au bout d’un certain temps de communication auprès du terrain pour qu’ils se responsabilisent sur l’hébergement de leurs données, chaque sous-orga low-tech s’équipe de son serveur semapps, et les données sont alors distribuées sur chacunes des instances, tout en gardant un lien.
Il faudrait d’ailleurs prévoir un outil (financé dans le chantier interrop ?) pour cette migration de « distribution »…
Qu’en pensez-vous ? Avons-nous déjà des super schémas pour ça ?
Sinon, j’en commence un sous Figma