Ce sujet fait suite à Une alternative temporaire à WebID-OIDC? pour continuer les échanges avec @srosset et @simon.louvet.zen.
Depuis le frontend d’un SemApps, comment permettre l’affichage de ressources situées sur un autre SemApps de manière authentifiée (via un même SSO) ?
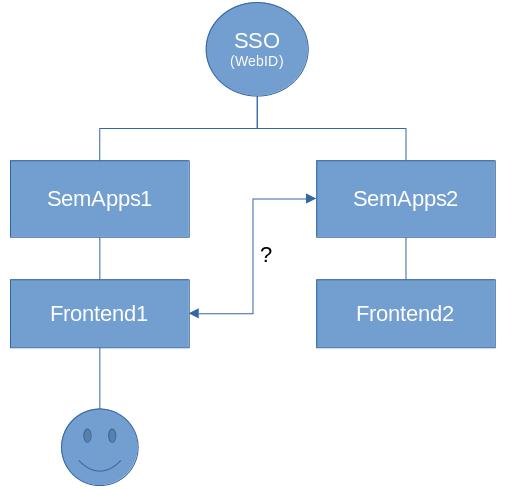
Nous avons pensé à l’idée de stocker le WebID de l’utilisateur dans le SSO commun aux deux SemApps. Actuellement, la normalisation du stockage du WebID est partagée entre plusieurs normes concurrentes. Pour le moment SemApps préfère l’implémenter d’une manière temporaire en attendant d’adopter une norme.
Mais alors comment mettre en œuvre ce stockage temporaire du WebID dans le SSO ?
Scenario 1 : utilisation normale de l’access_token
- L’utilisateur s’identifie sur le
SemApps1. Frontend1reçoit unid_tokenet unaccess_tokende lecture;Fontend1demande la ressource àSemApps2en fournissant l’access_tokende lecture;SemApps2vérifie ce token et récupère sonWebIDassocié via leuserinfoendpoint du SSO;SemApps2vérifie lesACLet renvoie la ressource correspondant auWebIDrécupéré précédemment àFrontend1.
En sachant qu’un mécanisme de cache peut être positionné sur l’étape 4.
Scenario 2 : utilisation détournée de l’id_token
- L’utilisateur s’identifie sur le
SemApps1. SemApps1reçoit unid_tokencontenant leWebID;Fontend1demande la ressource àSemApps2en fournissant l’id_token;SemApps2vérifie l’id_tokenet lesACL;SemApps2renvoie la ressource correspondant auWebID(dans l’id_token) àFrontend1.
Scenario 3 : utilisation simplifiée de l’access_token
- L’utilisateur s’identifie sur le
SemApps1. SemApps1reçoit unid_tokenetFrontend1reçoit unaccess_tokende lecture contenant leWebIDde l’utilisateur;Fontend1demande la ressource àSemApps2en fournissant l’access_tokende lecture;SemApps2vérifie l’access_tokenet lesACL;SemApps2renvoie la ressource correspondant auWebID(dans l’access_token) àFrontend1.
D’après moi le scenario 1 est celui qui respecte le « mieux » la norme OIDC en séparant bien l’id_token de l’access_token. En effet, l’id_token n’est pas sensé être utilisé pour demander l’accès à une ressource mais pour identifier un utilisateur. Imaginez qu’un SemApps2 malicieux pourrait utiliser cet id_token pour agir en tant que l’utilisateur de façon malveillante. Alors qu’avec seulement un access_token de lecture en main ce serveur malicieux ne pourrait pas faire grand chose à part lire des données.
Le scenario 3 simplifie les choses mais contredit le rôle de l’access_token qui est d’autoriser et pas d’identifier. Cependant, une récente RFC, indique qu’il est possible de mettre des infos d’identification dans un access_token dans le cas où l’on requête son propre backend (ce qui n’est pas le cas ici) :
This is particularly common in scenarios where the client and the resource server belong to the same entity and are part of the same solution, as is the case for first-party clients invoking their own backend API.
Nous devons également faire face à un autre problème de taille : l’API de modification des user_claims du SSO (attributs utilisateur) est accessible avec un simple access_token. Cela signifie qu’un utilisateur pourrait modifier son WebID lui-même dans le SSO et donc se faire passer pour quelqu’un d’autre !